三.多机数据库的实现
1.复制
在Redis中,用户可以通过slaveof命令或者slaveof选项实现,让一个服务器去复制(replicate)另一个服务器。
1.1旧版复制功能的实现(2.8版前)
Redis的复制功能主要分为*同步*和*命令传播*两步:
- 同步:将slave的状态更新至master的状态
- 命令传播:当master的状态改变时,让主从服务器的状态重回一致
1.1.1同步
slave对master的同步操作需要通过向master发送sync命令来完成,sync命令的执行步骤:
- slave发送sync命令
- 收到sync命令的master主服务器执行bgsave命令,在后台生成一个rdb文件,并使用一个缓冲区记录从现在开始执行的所有写命令
- master将rdb文件发送给slave,slave将自身状态更新至rdb的状态
- master将缓冲区里面的命令发送给slave,slave执行这些命令,将自己数据状态更新至主服务器当前所处状态。(master在发送过程中接收到的写命令怎么处理?)
1.1.2命令传播
当master执行写命令时,将命令发送给slave,使得二者状态一致
1.2旧版复制功能的缺陷
在Redis中,从服务器对主服务器的复制可以两种情况:
- 初次复制
- 断线后重复制:slave再次发送sync命令,再次生成rdb文件,而rdb文件中的大部分键是已经同步过的(非必要的)。
1.3新版复制功能的实现(>=2.8版)
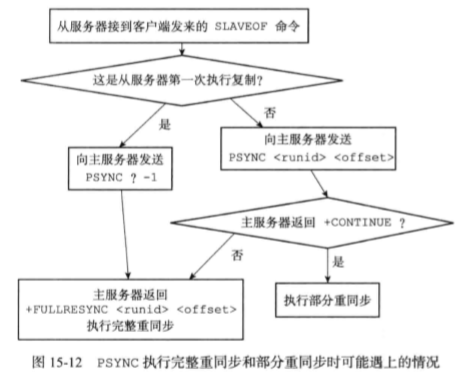
使用psync命令代替sync命令来执行复制时的同步操作。psync具有*完整重同步*和*部分重同步*两种模式。
- 完整重同步:用于处理初次复制情况,完整的执行步骤与sync命令的执行步骤基本一样。
- 部分重同步:用于处理断线后复制情况。当断线重连后,如果条件允许,master可以将断开期间执行的写命令发送给slave。
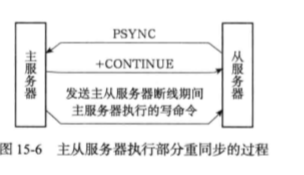
1.4部分重同步的实现
部分重同步功能主要由以下三个部分构成:
- master的复制偏移量和slave的复制偏移量
- master的复制挤压缓冲区
- master的运行ID
1.4.1复制偏移量
master和slave分别维护一个*复制偏移量*:
- master每次向slave传播N个字节的数据时,就在自己的复制偏移量
offset上加N - slave每次收到master传播来的N个字节的数据时,在自己的复制偏移量
offset上加N
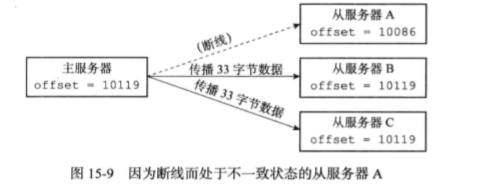
通过对比master和slave的偏移量,可以判断出主从服务器是否处于一致状态。slave向master发送psync时,会带上自己的复制偏移量。
1.4.2复制积压缓冲区
问题:
- master如何判断是完整重同步还是部分重同步?
- 如果执行部分重同步的话,master如何补偿slave断线期间丢失的数据?
复制积压缓冲区时由master维护的一个固定长度的队列,默认大小为1MB(可根据需要调整)。当master进行命令传播时,它不仅会将写命令发送给所有slave,还会将写命令入队到复制积压缓冲区里面。
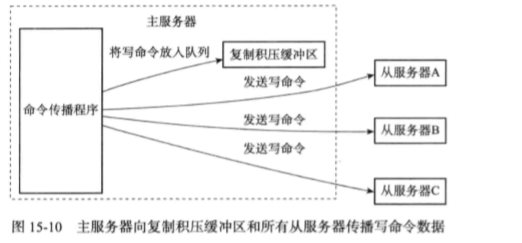
当slave连上master时,会通过psync命令将自己的复制偏移量offset发送给master,master通过offset决定执行何种操作:(问题1的答案)
- 如果offset之后的数据已经不存在与复制积压缓冲区,会执行完整重同步
- 如果存在,会执行部分重同步,将复制积压缓冲区offset后的内容发送给slave
1.4.3服务器运行ID
实现部分重同步还需要用到服务器运行ID,运行ID在服务器(不论master和slave)启动时自动生成,由40个随机的十六进制字符组成。当salve初次对master进行复制时,master会把自己的运行ID传送给slave,slave会把这个运行ID存起来(slave也有自己的运行ID)
在slave断开重连时,slave向master发送之前保存的masterID,如果masterID与当前的master的运行ID相同,说明slave断线前复制的就是当前的master,可以继续尝试*部分重同步*,否则执行*完整重同步*。
1.5psync命令执行流程
1.6复制的实现
- 步骤1:设置主服务器的地址和端口,设置
redisServer的char *masterhost和int masterport字段。 - 步骤2:建立套接字连接,slave是master的客户端
- 步骤3:发送ping命令,假警察套接字的状态是否正常。
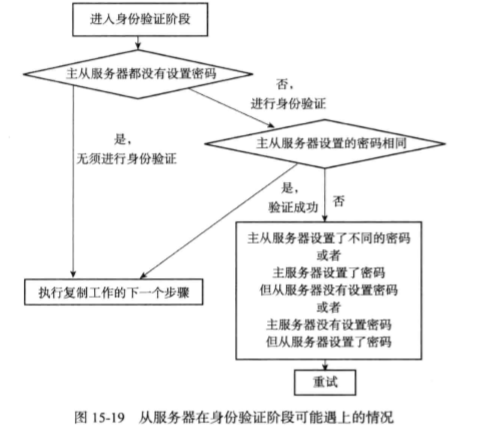
- 步骤4:身份验证
- 步骤5:发送端口信息,slave执行
replconf listening-port <port-number>,master接收到这个命令后,会将端口号记录在redisClient的slave_listening_port字段中。 - 步骤6:同步,slave发送psync命令
- 步骤7: 命令传播,master将写命令发送给slave
1.7心跳检测
在命令传播阶段,slave默认会以每秒一次的频率,向主服务器发命令:replconf ack <replication_offset>
发送replconf ack命令有三个作用:
- 检测主从服务器的网络连接状态
- 辅助实现min-slaves选项:redis的
min-slaves-to-write(从服务数量)和min-slaves-max-lag(延迟)两个选项可以防止master在不安全的状态下执行写命令。 - 检测命令丢失:如果因为网络故障,写命令丢失,那么当发送ack命令时,服务器会发觉写命令丢失,会重新发送丢失的写命令。
2.哨兵
sentinel是Redis的高可用性解决方案:由一个或多个sentinel组成的sentinel系统可以监视任意多个master,以及这些服务器属下的所有slave,并且在被监视的master进入下线状态时,自动将下线master的某个slave升级为新的master,然后由新master代替已下线的主服务器处理命令请求。
2.1启动并初始化sentinel
启动一个sentinel使用命令:
redis-sentinel /xxx/sentinel.conf 或 redis-server /xxx/sentinel.conf --sentinel
2.1.1初始化服务器
sentinel本质是一个运行在特殊模式下的Redis服务器,因为sentinel不使用数据库,所以sentinel在初始化时不用加载rdb或者aof文件。
2.1.2使用sentinel专用代码
REDIS_SERVERPORT->REDIS_SENTINEL_PORT
redisCommandTable->sentinelcmd
2.1.3初始化sentinel状态
初始化一个 sentinelState结构
/* Main state. */
/* Sentinel 的状态结构 */
struct sentinelState {
// 当前纪元
uint64_t current_epoch; /* Current epoch. */
// 保存了所有被这个 sentinel 监视的主服务器
// 字典的键是主服务器的名字
// 字典的值则是一个指向 sentinelRedisInstance 结构的指针
dict *masters; /* Dictionary of master sentinelRedisInstances.
Key is the instance name, value is the
sentinelRedisInstance structure pointer. */
// 是否进入了 TILT 模式?
int tilt; /* Are we in TILT mode? */
// 目前正在执行的脚本的数量
int running_scripts; /* Number of scripts in execution right now. */
// 进入 TILT 模式的时间
mstime_t tilt_start_time; /* When TITL started. */
// 最后一次执行时间处理器的时间
mstime_t previous_time; /* Last time we ran the time handler. */
// 一个 FIFO 队列,包含了所有需要执行的用户脚本
list *scripts_queue; /* Queue of user scripts to execute. */
} sentinel;
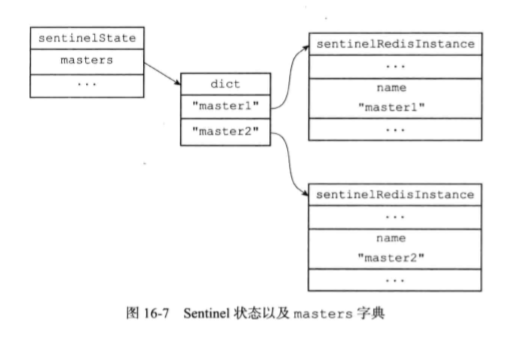
2.1.4初始化sentinel状态的masters属性
sentinel状态中的masters字典记录了所有被sentinel监视的主服务信息。字典的键是master的名字,字典的值是sentinelRedisInstance结构
// Sentinel 会为每个被监视的 Redis 实例创建相应的 sentinelRedisInstance 实例
// (被监视的实例可以是主服务器、从服务器、或者其他 Sentinel )
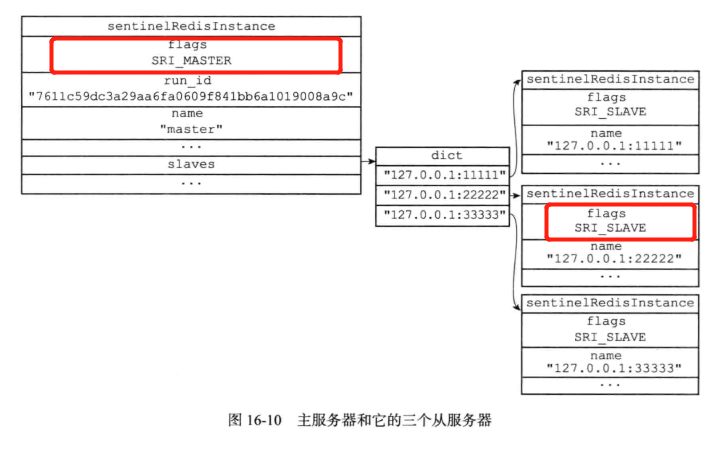
typedef struct sentinelRedisInstance {
// 标识值,记录了实例的类型,以及该实例的当前状态
int flags; /* See SRI_... defines */
// 实例的名字
// 主服务器的名字由用户在配置文件中设置
// 从服务器以及 Sentinel 的名字由 Sentinel 自动设置
// 格式为 ip:port ,例如 "127.0.0.1:26379"
char *name; /* Master name from the point of view of this sentinel. */
// 实例的运行 ID
char *runid; /* run ID of this instance. */
// 配置纪元,用于实现故障转移
uint64_t config_epoch; /* Configuration epoch. */
// 实例的地址
sentinelAddr *addr; /* Master host. */
// 用于发送命令的异步连接
redisAsyncContext *cc; /* Hiredis context for commands. */
// 用于执行 SUBSCRIBE 命令、接收频道信息的异步连接
// 仅在实例为主服务器时使用
redisAsyncContext *pc; /* Hiredis context for Pub / Sub. */
// 已发送但尚未回复的命令数量
int pending_commands; /* Number of commands sent waiting for a reply. */
...
}
2.1.5 创建连向主服务器的网络连接
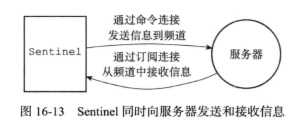
sentinel将成为master的客户端,对于每个被sentinel监视的master说,sentinel会创建两个异步连接:
- 一个是命令连接,用于向master发送命令,并接受命令回复
- 另一个是订阅连接,用于订阅master的sentinel:hello频道;因为在目前的发布订阅功能中,被发送的信息不会存在redis服务器里面,如果在消息发送时,客户端掉线,那么客户端会丢失这条消息。为了不丢失sentinel:hello频道的任何消息,必须专门用一个订阅连接来接收该频道的消息??(这个理由没看懂,订阅sentinel频道和消息丢失有啥关系???订阅能保证消息不丢失??)
2.2获取master信息
sentinel默认以每10s一次的频率,通过命令连接项监视的master发送info命令,将会获取类似以下的回复:
# Server
...
run_id:7611cXXXXXXXXXXX
...
# Replication
role:master
...
slave0:ip=127.0.0.1,port=11111,state=online,offset=43,lag=0
slave1:ip=127.0.0.1,port=11112,state=online,offset=43,lag=0
slave2:ip=127.0.0.1,port=11113,state=online,offset=43,lag=0
...
通过info命令回复,sentinel可以获取master及其slaves的信息,sentinel根据信息对master实例结构进行更新。
2.3获取slave信息
当sentinel发现master有slave出现时,sentinel会为这个新的slave创建实例结构,还会创建到新slave的命令连接与订阅。在创建命令连接后,sentinel在默认的情况下,会以10s一次的频率向slaves发送info命名,根据命令的回复更新slave的实际结构。

2.4向master和slave发送信息
在默认情况下,sentinel以2s一次的频率通过*命令连接*向所有监视的master和slave发送:
publish __sentinel__:hello "<s_ip>,<s_port>,<s_runid>,<s_epoch>,<m_name>,<m_ip>,<m_port>,<m_epoch>"
其中以s_开头的参数记录sentinel的信息,以m_开头的记录master的信息。
2.5接收来自master和slave的频道信息
当sentinel与一个服务器建立起订阅连接之后,sentinel会订阅__sentinel__:hello频道的信息。
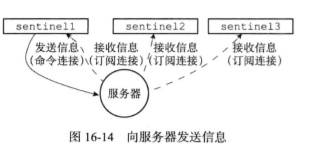
当一个sentinel从频道收到一条信息时,会提取出其中的sentinel_ip,sentinel_port等参数,根据参数更新master的sentinels字典,并创建连向其他sentinel的命令连接(sentinel之间不创建订阅连接,而是根据master发来的频道信息发现未知新的sentinel)。
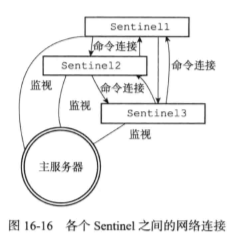
2.6检测主观下线状态
sentinel以每秒1次的频率向所有与它创建了命令连接的服务器(包括master,slave,其他sentinel)发送ping命令,根据回复判断实例是否在线,如果一个实例在down-after-milliseconds(主观下线时长,多个sentinel的配置可能不同)毫秒内,连续向sentinel返回无效回复,那么sentinel会将实例判定为主观下线状态,然后修改这个实例对应的实例结构(在flags中打开SRI_S_DOWN标识)。

2.7检查客观下线状态
当sentinel将一个主服务器判断为主观下线后,为了确认这个主服务器是否真的下线了,它会向同样监视这一个主服务器的其他sentinel进行询问,当从其他sentinel接收到足够数量(quorum)的已下线判断后,sentinel会将服务器判定为客观下线(不同的sentinel判断客观下线的条件可能不同),并修改主服务实例结构的flags属性,并对主服务执行故障转移操作。
sentinel使用:
sentinel is-master-down-by-addr <ip> <port> <current_epoch> <runid> 命令询问其他sentinel是否同意主服务已下线。
| 参数 | 意义 |
| :- | :- |
| ip | 被sentinel判断为主观下线的主服务器的IP地址 |
| port | 被sentinel判断为主观下线的主服务器的端口号 |
| cunrrent_epoch | sentinel当前的配置纪元,用于选举领头sentinel |
| runid | 可以是*或者sentinel的运行id。*代表仅仅用于检测主服务器的客观下线状态,而sentinel的运行ID用于选举领头sentinel |
当一个sentinel接收到sentinel is-master-down-by-addr命令时,会根据参数检查主服务器是否以下线,然后回复包含三个参数的multi bulk:
- <down_state>
- <leader_runid>
- <leader_epoch>
2.8选举领头sentinel
采用raft算法的领头选举方法(略)。
2.9故障转移
三个步骤:
- 在已下线服务器属下的所有从服务器中,挑选出一个从服务器,发送
slaveof no one命令,将这个从服务器转换为主服务器。 - 修改其他从服务器的复制目标,向其发送
slaveof <ip> <port>命令,使其将第一步选出的服务器作为新的主服务器。 - 当旧主服务器重新上线时,将其设置为从服务器。
3.集群
集群通过分片来进行数据共享,并提供复制和故障转移功能。
3.1节点
3.1.1启动节点
一个节点就是一个运行在集群模式下的redis服务器,redis服务器在启动时会根据cluster-enable配置选项来决定是否开启服务器的集群模式。集群模式的节点会继续使用单机模式的组件(功能)。
3.1.2集群数据结构
clusterNode来记录节点状态,并为其他节点都创建一个相应的clusterNode结构。
// 节点状态
struct clusterNode {
// 创建节点的时间
mstime_t ctime; /* Node object creation time. */
// 节点的名字,由 40 个十六进制字符组成
// 例如 68eef66df23420a5862208ef5b1a7005b806f2ff
char name[REDIS_CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
// 节点标识
// 使用各种不同的标识值记录节点的角色(比如主节点或者从节点),
// 以及节点目前所处的状态(比如在线或者下线)。
int flags; /* REDIS_NODE_... */
// 节点当前的配置纪元,用于实现故障转移
uint64_t configEpoch; /* Last configEpoch observed for this node */
...
// 保存连接节点所需的有关信息
clusterLink *link; /* TCP/IP link with this node */
// 一个链表,记录了所有其他节点对该节点的下线报告
list *fail_reports; /* List of nodes signaling this as failing */
};
clusterLink保存了连接节点的信息。
/* clusterLink encapsulates everything needed to talk with a remote node. */
// clusterLink 包含了与其他节点进行通讯所需的全部信息
typedef struct clusterLink {
// 连接的创建时间
mstime_t ctime; /* Link creation time */
// TCP 套接字描述符
int fd; /* TCP socket file descriptor */
// 输出缓冲区,保存着等待发送给其他节点的消息(message)。
sds sndbuf; /* Packet send buffer */
// 输入缓冲区,保存着从其他节点接收到的消息。
sds rcvbuf; /* Packet reception buffer */
// 与这个连接相关联的节点,如果没有的话就为 NULL
struct clusterNode *node; /* Node related to this link if any, or NULL */
} clusterLink;
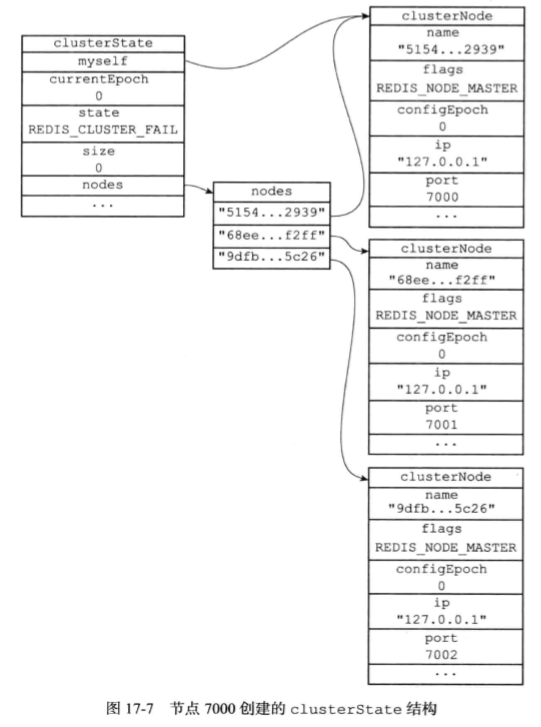
clusterState记录了在当前节点的视角下,集群目前所处的状态。
// 集群状态,每个节点都保存着一个这样的状态,记录了它们眼中的集群的样子。
// 另外,虽然这个结构主要用于记录集群的属性,但是为了节约资源,
// 有些与节点有关的属性,比如 slots_to_keys 、 failover_auth_count
// 也被放到了这个结构里面。
typedef struct clusterState {
// 指向当前节点的指针
clusterNode *myself; /* This node */
// 集群当前的配置纪元,用于实现故障转移
uint64_t currentEpoch;
// 集群当前的状态:是在线还是下线
int state; /* REDIS_CLUSTER_OK, REDIS_CLUSTER_FAIL, ... */
// 集群中至少处理着一个槽的节点的数量。
int size; /* Num of master nodes with at least one slot */
// 集群节点名单(包括 myself 节点)
// 字典的键为节点的名字,字典的值为 clusterNode 结构
dict *nodes; /* Hash table of name -> clusterNode structures */
// 节点黑名单,用于 CLUSTER FORGET 命令
// 防止被 FORGET 的命令重新被添加到集群里面
// (不过现在似乎没有在使用的样子,已废弃?还是尚未实现?)
dict *nodes_black_list; /* Nodes we don't re-add for a few seconds. */
...
// 通过 cluster 连接发送的消息数量
long long stats_bus_messages_sent; /* Num of msg sent via cluster bus. */
// 通过 cluster 接收到的消息数量
long long stats_bus_messages_received; /* Num of msg rcvd via cluster bus.*/
} clusterState;
3.1.3cluster meet命令的实现
cluster meet <ip> <port>可以让当前节点与指定的节点进行握手,当握手成功时,node节点会将指定节点添加到当前集群中。
握手过程:
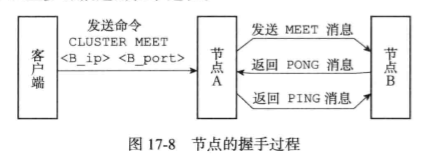
之后,节点A会将节点B的信息通过Gossip协议传播给集群中的其他节点,让其他节点与节点B进行握手。
3.2槽指派
Redis集群通过分片的方式来保存数据库中的键值对,几区的整个数据库被分为16384个槽,数据库中的每个键都属于16384个槽中的一个。
cluster addslots <slot> [slot ...] :将一个或多个槽指派给当前节点负责。
3.2.1记录节点的槽指派信息
struct clusterNode{
....
// 由这个节点负责处理的槽
// 一共有 REDIS_CLUSTER_SLOTS / 8 个字节长
// 每个字节的每个位记录了一个槽的保存状态
// 位的值为 1 表示槽正由本节点处理,值为 0 则表示槽并非本节点处理
// 比如 slots[0] 的第一个位保存了槽 0 的保存情况
// slots[0] 的第二个位保存了槽 1 的保存情况,以此类推
unsigned char slots[REDIS_CLUSTER_SLOTS/8]; /* slots handled by this node */
// 该节点负责处理的槽数量
int numslots; /* Number of slots handled by this node */
...
};
3.2.2传播节点的槽指派信息
集群中的每个节点都会将自己的slots数组通过消息发送给集群中的其他节点,并且每个接收到slots数组的节点都会讲数据保存到响应节点的clusterNode结构中,集群中的每个节点都会知道数据库中的16384个槽分别指派给了集群中的哪些节点。
3.2.3记录集群所有槽的指派信息
clusterState结构中的slots数组记录了所有16384个槽的指派信息。
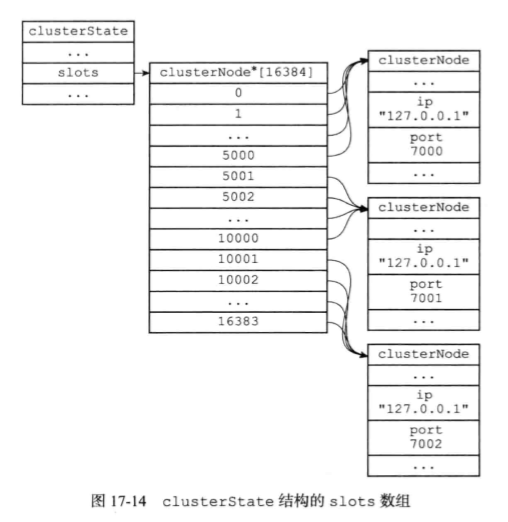
3.3在集群中执行命令
3.3.1计算键属于哪个槽
def slot_number(key):
return CRC16(key) & 16383
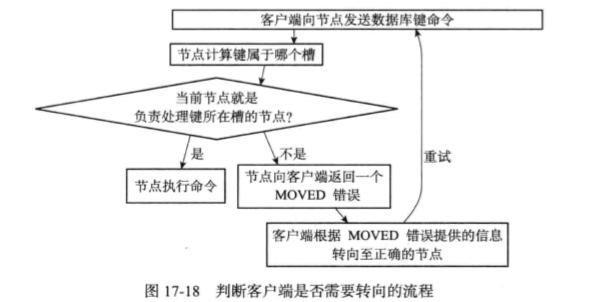
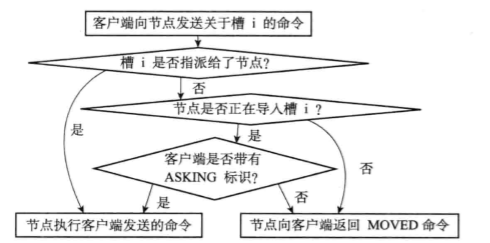
3.3.2判断槽是否有当前节点负责
计算出键所属的槽i之后,节点会检查自己在clusterState.slots数组中的项i:
- 如果clusterState.slots[i]等于clusterState.myself,则说明由当前节点负责,节点可以执行客户端发送的命令
- 否则,节点会向客户端返回MOVED错误,指引客户端转向正在处理槽i的节点
3.3.3MOVED错误
moved <slot> <ip>:<port>


3.3.4节点数据库的实现
集群节点保存键值对即键值对过期时间的方式,与单机Redis服务器相同;一个区别:节点只能使用0号数据库,而redis服务器则没有这一限制。
节点会用clusterState结构中的zskiplist *slots_to_keys来保存槽与键之间的关系,节点可以很方便的对属于某些槽里的所有数据库键进行批量操作。
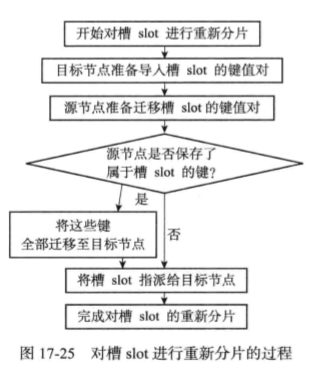
3.4重新分片
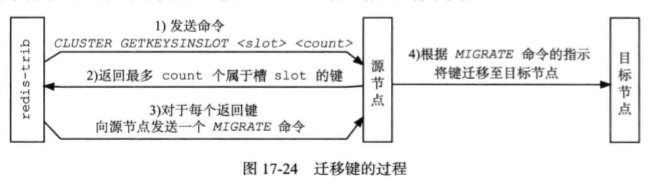
Redis集群的重新分片操作可以将任意数量已经指派给某个节点(源节点)的槽指派给另一个节点(目标节点),并且相关槽所属的键值对也会从源节点移动到目标节点。重新分片是通过redis-trib负责执行的,redis-trib对集群的单个槽的重新分片步骤:
- 对目标节点发送
cluster setslot <slot> importing <source_id>命令 - 对源节点发送
cluster setslot <slot> migrate <target_id>命令 - 向源节点大送给
cluster getkeyinslot <slot> <count> - 对于步骤3获得的每个键名,向源节点发送一个
migrate <target_ip> <target_port> <key_name> 0 <time_out> - 重复3,4
- 向集群中的任一个节点发送
cluster setslot <slot> node <target_id>命令
3.5 ASK错误
在重新分片期间,可能出现:属于被迁移槽的一部分键值对保存在源节点里,而另一部分保存在目标节点里。 当节点收到一个关于键key的请求,如果节点没有在自己的数据库里找到键key,则会检查自己的clusterState.migrating_slots_to[i],看键key所述的槽i是否正在迁移,如果正在迁移,则向客户端返回ask错误。
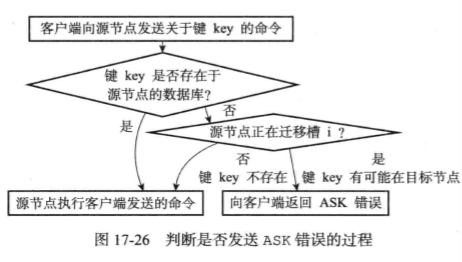
asking命令
asking命令:打开发送该命令的客户端的redis_asking标识。注:redis_asking是一次性标识。
ask错误与moved错误的区别
ask错误与moved错误都会导致客户端转向,区别在于:
- moved代表操的负责权已经从一个节点转移到了另一个节点。
- ask错误是两个节点在迁移过程中使用的一种临时措施。
3.6复制与故障转移
集群中的节点分为主节点和从节点,主节点用于处理槽,从节点用于复制某个主节点,并在被复制的主节点下线时,代替下线节点继续处理命令请求。
3.7消息
节点发送的消息主要有5种:
- meet
- ping
- pong
- fail
- publish
消息由消息头和消息正文组成。
// 用来表示集群消息的结构(消息头,header)
typedef struct {
char sig[4]; /* Siganture "RCmb" (Redis Cluster message bus). */
// 消息的长度(包括这个消息头的长度和消息正文的长度)
uint32_t totlen; /* Total length of this message */
uint16_t ver; /* Protocol version, currently set to 0. */
uint16_t notused0; /* 2 bytes not used. */
// 消息的类型
uint16_t type; /* Message type */
// 消息正文包含的节点信息数量
// 只在发送 MEET 、 PING 和 PONG 这三种 Gossip 协议消息时使用
uint16_t count; /* Only used for some kind of messages. */
// 消息发送者的配置纪元
uint64_t currentEpoch; /* The epoch accordingly to the sending node. */
// 如果消息发送者是一个主节点,那么这里记录的是消息发送者的配置纪元
// 如果消息发送者是一个从节点,那么这里记录的是消息发送者正在复制的主节点的配置纪元
uint64_t configEpoch; /* The config epoch if it's a master, or the last
epoch advertised by its master if it is a
slave. */
// 节点的复制偏移量
uint64_t offset; /* Master replication offset if node is a master or
processed replication offset if node is a slave. */
// 消息发送者的名字(ID)
char sender[REDIS_CLUSTER_NAMELEN]; /* Name of the sender node */
// 消息发送者目前的槽指派信息
unsigned char myslots[REDIS_CLUSTER_SLOTS/8];
// 如果消息发送者是一个从节点,那么这里记录的是消息发送者正在复制的主节点的名字
// 如果消息发送者是一个主节点,那么这里记录的是 REDIS_NODE_NULL_NAME
// (一个 40 字节长,值全为 0 的字节数组)
char slaveof[REDIS_CLUSTER_NAMELEN];
char notused1[32]; /* 32 bytes reserved for future usage. */
// 消息发送者的端口号
uint16_t port; /* Sender TCP base port */
// 消息发送者的标识值
uint16_t flags; /* Sender node flags */
// 消息发送者所处集群的状态
unsigned char state; /* Cluster state from the POV of the sender */
// 消息标志
unsigned char mflags[3]; /* Message flags: CLUSTERMSG_FLAG[012]_... */
// 消息的正文(或者说,内容)
union clusterMsgData data;
} clusterMsg;
union clusterMsgData {
/* PING, MEET and PONG */
struct {
/* Array of N clusterMsgDataGossip structures */
// 每条消息都包含两个 clusterMsgDataGossip 结构
clusterMsgDataGossip gossip[1];
} ping;
/* FAIL */
struct {
clusterMsgDataFail about;
} fail;
/* PUBLISH */
struct {
clusterMsgDataPublish msg;
} publish;
/* UPDATE */
struct {
clusterMsgDataUpdate nodecfg;
} update;
};
/* Initially we don't know our "name", but we'll find it once we connect
* to the first node, using the getsockname() function. Then we'll use this
* address for all the next messages. */
typedef struct {
// 节点的名字
// 在刚开始的时候,节点的名字会是随机的
// 当 MEET 信息发送并得到回复之后,集群就会为节点设置正式的名字
char nodename[REDIS_CLUSTER_NAMELEN];
// 最后一次向该节点发送 PING 消息的时间戳
uint32_t ping_sent;
// 最后一次从该节点接收到 PONG 消息的时间戳
uint32_t pong_received;
// 节点的 IP 地址
char ip[REDIS_IP_STR_LEN]; /* IP address last time it was seen */
// 节点的端口号
uint16_t port; /* port last time it was seen */
// 节点的标识值
uint16_t flags;
// 对齐字节,不使用
uint32_t notused; /* for 64 bit alignment */
} clusterMsgDataGossip;
typedef struct {
// 下线节点的名字
char nodename[REDIS_CLUSTER_NAMELEN];
} clusterMsgDataFail;
typedef struct {
// 频道名长度
uint32_t channel_len;
// 消息长度
uint32_t message_len;
// 消息内容,格式为 频道名+消息
// bulk_data[0:channel_len-1] 为频道名
// bulk_data[channel_len:channel_len+message_len-1] 为消息
unsigned char bulk_data[8]; /* defined as 8 just for alignment concerns. */
} clusterMsgDataPublish;